12.12 Mindformers-chatglm-6b训练&推理&微调总结
1.推理
权重文件目录:
1.1.方式一:AutoClass
可以使用AutoClass接口,通过模型名称获取相应的模型/tokenizer实例,并自动下载并加载权重 from_pretrained() 接口会自动从云上下载预训练的模型,存储路径:当前执行脚本目录下的 ./checkpoint_download/glm 首次运行pipeline推理时需要进行模型编译,需等待一段时间 from mindformers import AutoModel, AutoTokenizer, TextGenerationPipeline model = AutoModel.from_pretrained("glm_6b_chat") tokenizer = AutoTokenizer.from_pretrained("glm_6b") pipeline = TextGenerationPipeline(model, tokenizer, max_length=2048) print(pipeline("你好"))
#eg:[{'text_generation_text': ['你好 你好���!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。']}]
1.2.方式二:pipeline
也可以不实例化构造模型,直接通过指定任务模型与模型名的方式进行pipeline的构造 pipeline中,也可以使用 glm_6b_chat 模型加速推理 from mindformers import pipeline task_pipeline = pipeline(task="text_generation", model="glm_6b_chat", max_length=2048) print(task_pipeline("你好"))
#eg:[{'text_generation_text': ['你好 你好���!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。']}]
1.3.方式三: API接口
import time
import mindspore as ms
import numpy as np
from mindformers.models.glm import GLMConfig, GLMChatModel
from mindformers.models.glm.chatglm_6b_tokenizer import ChatGLMTokenizer
from mindformers.models.glm.glm_processor import process_response
config = GLMConfig(
position_encoding_2d=True,
use_past=True,
is_npu_acceleration=True,
)
def chat_glm():
ms.set_context(mode=ms.GRAPH_MODE, device_target="Ascend", device_id=7)
model = GLMChatModel(config)
ms.load_checkpoint("./checkpoint_download/glm/glm_6b.ckpt", model)
tokenizer = ChatGLMTokenizer('./checkpoint_download/glm/ice_text.model')
prompts = ["你好", "请介绍一下华为"]
history = []
for query in prompts:
if not history:
prompt = query
else:
prompt = ""
for i, (old_query, response) in enumerate(history):
prompt += "[Round {}]\n问:{}\n答:{}\n".format(i, old_query, response)
prompt += "[Round {}]\n问:{}\n答:".format(len(history), query)
inputs = tokenizer(prompt)
start_time = time.time()
outputs = model.generate(np.expand_dims(np.array(inputs['input_ids']).astype(np.int32), 0),
max_length=config.max_decode_length, do_sample=False, top_p=0.7, top_k=1)
end_time = time.time()
print(f'generate speed: {outputs[0].shape[0]/(end_time-start_time):.2f} tokens/s')
response = tokenizer.decode(outputs)
response = process_response(response[0])
history = history + [(query, response)]
print(response)
if __name__ == "__main__":
chat_glm()
2.微调
2.1.微调数据集
1.ADGEN数据集下载地址:
https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1 解压数据集放在自定义指定目录
eg: /home/ma-user/work/dataset/
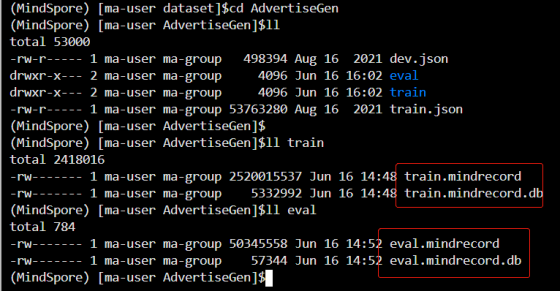
2.数据集转mindrecord格式
#生成训练数据集
python adgen_dataset.py --input_file /home/ma-user/work/dataset/AdvertiseGen/train.json --vocab_file /home/ma-user/work/mindformers/mycode/glm/checkpoint_download/glm/ice_text.model --output_file /home/ma-user/work/dataset/AdvertiseGen/train/train.mindrecord --max_source_length 64 --max_target_length 64 --mode train
生成评估数据集
python adgen_dataset.py --input_file /home/ma-user/work/dataset/AdvertiseGen/dev.json --vocab_file /home/ma-user/work/mindformers/mycode/glm/checkpoint_download/glm/ice_text.model --output_file /home/ma-user/work/dataset/AdvertiseGen/eval/eval.mindrecord --max_source_length 256 --max_target_length 256 --mode eval
2.2.裸机环境生成HCCL文件(参考) 运行mindformers/tools/hccl_tools.py生成RANK_TABLE_FILE的json文件;
step1:机器上运行如下命令,生成各自的RANK_TABLE_FILE的json文件
python ./mindformers/tools/hccl_tools.py --device_num "[0,8)" 注:若使用ModelArts的notebook环境,可从 /user/config/jobstart_hccl.json 路径下直接获取rank table,无需手动生成 RANK_TABLE_FILE 单机8卡参考样例: { "version":"1.0", "server_count":"1", "server_list":[ { "server_id":"xx.xx.xx.xx", "device":[ {"device_id":"0","device_ip":"192.1.27.6","rank_id":"0"}, {"device_id":"1","device_ip":"192.2.27.6","rank_id":"1"}, {"device_id":"2","device_ip":"192.3.27.6","rank_id":"2"}, {"device_id":"3","device_ip":"192.4.27.6","rank_id":"3"}, {"device_id":"4","device_ip":"192.1.27.7","rank_id":"4"}, {"device_id":"5","device_ip":"192.2.27.7","rank_id":"5"}, {"device_id":"6","device_ip":"192.3.27.7","rank_id":"6"}, {"device_id":"7","device_ip":"192.4.27.7","rank_id":"7"}], "host_nic_ip":"reserve" } ], "status":"completed" }
2.3.全参微调
2.3.1.run_mindformers脚本启动全参微调
全参微调使用 configs/glm/run_glm_6b_finetune.yaml 配置文件,配置文件中定义了微调所需的各配置项 修改数据集/模型权重配置路径:
1.数据集:修改 mindformers/configs/glm/run_glm_6b_finetune.yaml 脚本中 train_dataset 的 dataset_dir 为前文生成的数据集路径。
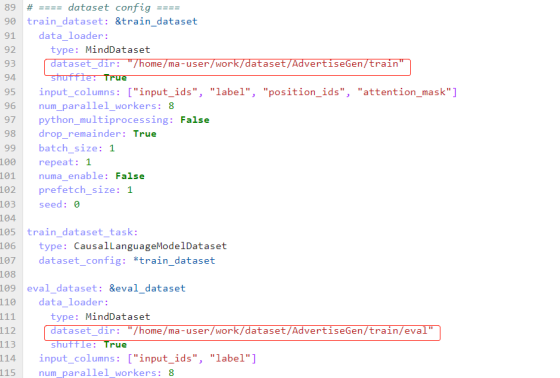
2.加载预训练模型权重:修改 mindformers/configs/glm/run_glm_6b_finetune.yaml 脚本中的 load_checkpoint 为预训练模型权重路径。

3.启动全参微调脚本:
cd scripts
# Usage Help: bash run_distribute.sh [RANK_TABLE_FILE] [CONFIG_PATH] [DEVICE_RANGE] [RUN_STATUS]
bash run_distribute.sh /user/config/nbstart_hccl.json ../configs/glm/run_glm_6b_finetune.yaml '[0,8]' finetune
# 将此处rank_table_file替换为实际路径, 本例为notebook环境
参数说明
RANK_TABLE_FILE: 由mindformers/tools/hccl_tools.py生成的分布式json文件
CONFIG_PATH: 为configs文件夹下面的glm/run_glm_6b.yaml配置文件
DEVICE_RANGE: 为单机分布式卡的范围,如 '[0,8]' 为8卡分布式,不包含8本身
RUN_STATUS: 为任务运行状态,支持关键字 train\finetune\eval\predict
注:由于GLM6B的模型较大,无法在单卡上运行,此处仅提供分布式启动脚本
4.训练日志:
2.4.LoRA低参微调
全参微调能够在微调数据集上取得良好效果,但存在遗忘预训练知识的现象 因此推荐使用低参微调算法,冻结原模型权重,仅在小规模参数量上进行训练,在微调数据集上取得良好效果的同时,缓解模型遗忘现象
2.4.1.run_mindformers脚本启动LoRA低参微调
使用LoRA算法进行低参微调时,使用 configs/glm/run_glm_6b_lora.yaml 配置文件,该配置文件包含了lora低参微调算法所需的配置项 修改数据集/模型权重配置路径:
1.数据集:修改 mindformers/configs/glm/run_glm_6b_lora.yaml 脚本中 train_dataset 的 dataset_dir 为前文生成的数据集路径。
2.加载预训练模型权重:修改 mindformers/configs/glm/run_glm_6b_lora.yaml 脚本中的 load_checkpoint 为预训练模型权重路径。
启动LoRA低参微调脚本(4卡): 注:因低参微调所需内存减少,此处用4卡并行即可训练,需重新生成4卡训练所需的rank table file 卡数根据实际进行配置,notebook默认生成hccl json文件,所以卡数根据实际情况配置
cd scripts
#Usage Help: bash run_distribute.sh [RANK_TABLE_FILE] [CONFIG_PATH] [DEVICE_RANGE] [RUN_STATUS]
bash run_distribute.sh /path/to/hccl_4p_0123_xxx.json ../configs/glm/run_glm_6b_lora.yaml '[0,4]' finetune
#将此处rank_table_file替换为实际路径
参数说明:
对比全参微调启动方式,仅将 CONFIG_PATH 项修改为configs文件夹下面的 glm/run_glm_6b_lora.yaml 配置文件,表示使用该接口进行 训练的log日志路径:mindformers/output/log checkpoint存储路径:mindformers/output/checkpoint
3.LoRA低参微调结果:

3.评估
3.1.模型权重文件合一
微调所得到的权重文件为根据模型切分策略切分后的权重,我们需要手动将切分权重合一,以用于评估和推理 获取模型切分策略文件: 在执行全参微调脚本时,模型完成编译后,将会在运行路径下,生成名为 ckpt_strategy.ckpt 的切分策略文件,将其保存;该文件的路径及名称在配置文件中配置
MindSpore提供了根据切分策略转换模型权重切分的接口,https://www.mindspore.cn/docs/zh-CN/r2.0/api_python/mindspore/mindspore.transform_checkpoints.html 执行以下python脚本,将8份模型文件合成一份
微调不存在该操作(因为本操作使用的是Mindspore1.10)
from mindspore import transform_checkpoints
transform_checkpoints(
src_checkpoints_dir="./output/checkpoint/", # 原切分权重文件夹
dst_checkpoints_dir="./target_checkpoint/", # 目标路径
ckpt_prefix="glm-6b", # .ckpt文件前缀名
src_strategy_file="ckpt_stragery.ckpt", # 步骤1中的切分策略文件路径
dst_strategy_file=None # None表示不切分,权重合一
)
执行完以上代码生成的权重文件大概63G+以上的ckpt文件,需要执行以下脚本进行裁剪,获取文件大概13G+, LoRa微调不存在该操作(因为本操作使用的是Mindspore1.10)
import mindspore as ms
from mindspore import context
context.set_context(device_target="CPU")
from mindformers.tools.register import MindFormerConfig
from mindformers.models.glm import GLMConfig,GLMChatModel
#使用automodel会加载预训练模型权重,要等很久。用下面这种方式不加载权重
config = GLMConfig(MindFormerConfig('./checkpoint_download/glm/glm_6b.yaml'))
model_from_config = GLMChatModel(config)
print("模型加载完成")
ckpt_path = "/home/ma-user/work/mindformers/target_checkpoint/rank_0/glm-6b.ckpt"
param_dict = ms.load_checkpoint(ckpt_path)
print("读取数据完成")
new_param_dict = {}
for key, value in param_dict.items():
if "adam" not in key.lower():
new_param_dict[key] = value
print("参数过滤完成")
# param_not_load, _ = ms.load_param_into_net(model_from_config, param_dict)
ms.load_param_into_net(model_from_config, param_dict)
print("加载完成")
ms.save_checkpoint(model_from_config, "/home/ma-user/work/mindformers/target_checkpoint/rank_0/glm-6b_new.ckpt")
注:transform_checkpoints 接口当前仅mindspore 2.0以上版本支持,如当前硬件环境只支持2.0以下版本,可以新建conda环境安装mindspore 2.0的cpu版本以执行该脚本
此外,非2.0版本的mindspore,在低参微调时,生成的切分策略文件将不包含被冻结的权重,导致权重文件合并失败;
此时,需将 mindformers/models/glm/glm.py 文件中有关LoRA冻结权重的代码注释后,重新运行微调脚本,获取到正确的切分策略文件后停止训练进程;
相关代码如下
@MindFormerRegister.register(MindFormerModuleType.MODELS)
class GLMForPreTrainingWithLora(GLMForPreTraining):
"""GLM Model for pretraining with LoRA
Args:
config (GLMConfig): The config of network.
"""
def __init__(self, config: GLMConfig = None, pet=None, **kwargs):
_ = kwargs
super().__init__(config)
# get Pet tuning model.
self.pet = pet
self.pet.pet_config.reg_rules = r'.*query_key_value*'
self.transformer = LoraAdapter.get_pet_model(self.transformer, self.pet.pet_config)
# freeze pretrained model
PetAdapter.freeze_pretrained_model(self, self.pet.pet_type) # 注释此行以生成新的策略文件
非2.0版本,Mindspore1.10版本,执行权重文件合并没有异常正常合并,合并权重文件大概1.2g,使用该文件进行评估才会报错,错误信息如下:
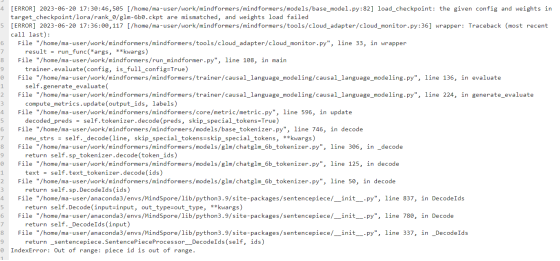
3.2.使用全参微调权重
3.2.1.run_mindformers启动eval
使用全参微调权重时,启动如下shell脚本,执行单卡评估 配置文件选择 configs/glm/run_glm_6b_infer.yaml
glm模型推理配置,此配置下评估速度更快。
python run_mindformer.py --config configs/glm/run_glm_6b_infer.yaml --run_mode eval --load_checkpoint /path/to/glm_6b.ckpt --eval_dataset_dir /path/to/data/AdvertiseGen/adgen_dev.mindrecord --device_id 0
各项参数:
config: 指定用于评估的配置文件名称,此处为 configs/glm/run_glm_6b_infer.yaml
run_mode: 指定执行模式,此为 eval,表示为评估模式
load_checkpoint: 指定要加载的checkpoint路径,此处为 /path/to/glm_6b.ckpt,替换为需加载的权重的真实路径
eval_dataset_dir: 评估数据集的路径
device_id: 指定要使用的设备编号(从0开始)
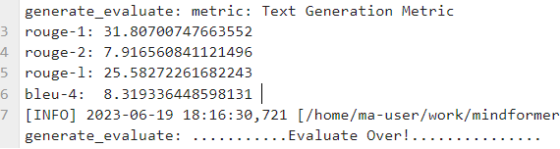
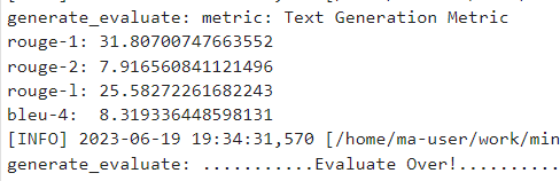
评估完成后会打印评估指标 bleu-4、rouge-1、rouge-2、rouge-l
注:由于默认评估指标的获取方式为生成完整文本后与预期文本做比较,评估速度将受限于模型大小与文本生成速度,评估流程可能较为缓慢
eval测试结果
63.5G未裁剪版ckpt:
13.5G裁剪过的ckpt:
3.3.使用LoRA低参微调权重
3.3.1.run_mindformers启动lora eval
使用LoRA低参微调权重时,启动如下shell脚本,执行单卡评估 配置文件选择 configs/glm/run_glm_6b_lora_infer.yaml glm_lora模型推理配置,此配置可用于lora模型,并且评估速度更快。
python run_mindformer.py --config configs/glm/run_glm_6b_lora_infer.yaml --run_mode eval --load_checkpoint /path/to/glm_6b_lora.ckpt --eval_dataset_dir /path/to/data/AdvertiseGen/adgen_dev.mindrecord --device_id 0
各项参数同上,路径需替换为实际路径
3.4.模型权重转化(参考)
本仓库中的 glm来自于HuggingFace的https://huggingface.co/THUDM/chatglm-6b 基于下述的步骤获取: 克隆chatglm-6b代码仓,下载分布式的模型文件。
git lfs install
git clone https://huggingface.co/THUDM/chatglm-6b
执行 python 脚本,合并模型权重。
from transformers import AutoModel
import torch as pt
pt_ckpt_path="Your chatglm-6b path"
model = AutoModel.from_pretrained(pt_ckpt_path, trust_remote_code=True).half()
pt_pth_path = "pt_glm_6b.pth"
pt.save(model.state_dict(), pt_pth_path)
执行转换脚本,得到转换后的输出文件 ms_glm_6b.ckpt。
python mindformers/models/glm/convert_weight.py --pt_ckpt_path "replace your ptroch pth path" --ms_ckpt_path ./ms_glm_6b.ckpt